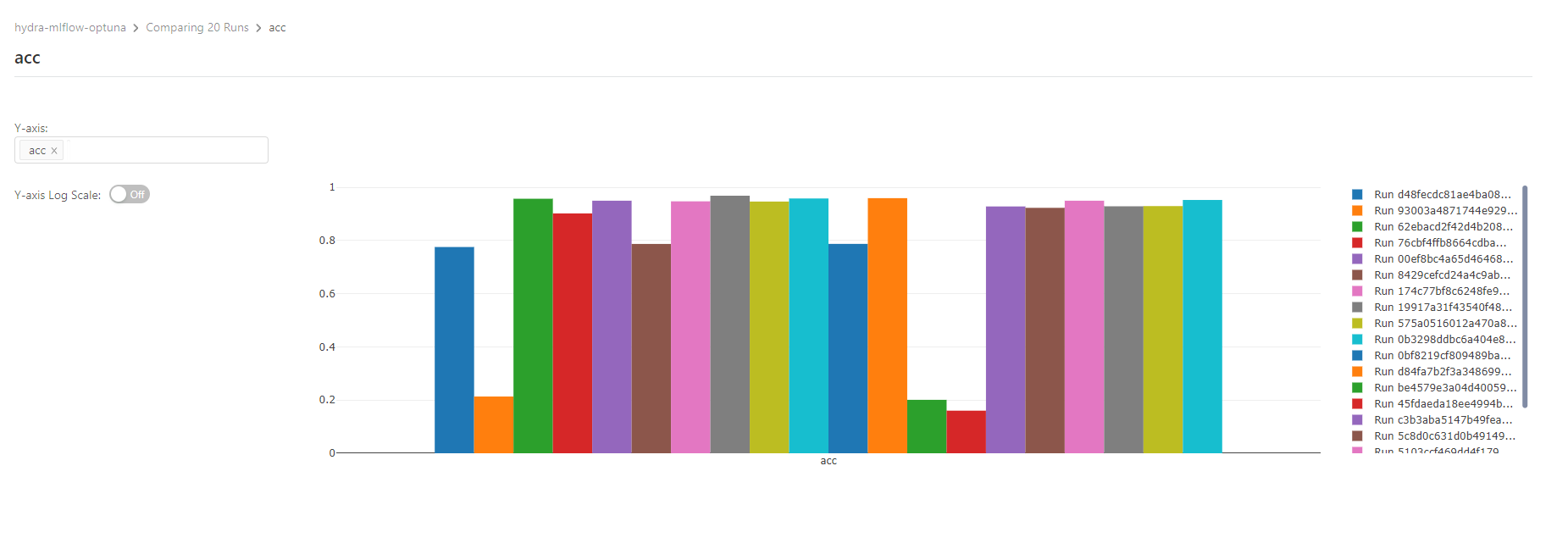
机器学习超参数调优可视可追踪可重复
在训练神经网络的时候,调节超参数是必不可少的,这个过程可以更科学地训练出更高效的机器学习模型。一般我们都是通过观察在训练过程中的监测指标如损失函数的值或者测试/验证集上的准确率来判断这个模型的训练状态,并通过修改超参数来提高模型效率。 本篇介绍如何通过开源组件Optuna, Hydra, MLflow构建一个超参数优化实验环境。 超参数 常规参数是在训练期间通过机器学习算法学习的参数,这些参数可以通过训练来优化。而超参数是设置如何训练模型的参数,它们有助于训练出更好的模型,超参数不能通过训练来优化。 超参优化 超参数优化是指不是依赖人工调参,而是通过一定算法找出优化算法/机器学习/深度学习中最优/次优超参数的一类方法。HPO的本质是生成多组超参数,一次次地去训练,根据获取到的评价指标等调节再生成超参数组再训练。 Optuna Optuna是机器学习的自动超参数优化框架,使用了采样和剪枝算法来优化超参数,快速而且高效,动态构建超参数搜索空间。 Optuna是一个超参数的优化工具,对基于树的超参数搜索进行了优化,它使用被称为TPESampler “Tree-structured Parzen Estimator”的方法,这种方法依靠贝叶斯概率来确定哪些超参数选择是最有希望的并迭代调整搜索。 Hydra Facebook Hydra 允许开发人员通过编写和覆盖配置来简化 Python 应用程序(尤其是机器学习方面)的开发。开发人员可以借助Hydra,通过更改配置文件来更改产品的行为方式,而不是通过更改代码来适应新的用例。 Hydra提供了一种灵活的方法来开发和维护代码及配置,从而加快了机器学习研究等领域中复杂应用程序的开发。 它允许开发人员从命令行或配置文件“组合”应用程序的配置。这解决了在修改配置时可能出现的问题,例如: 维护配置的稍微不同的副本或添加逻辑以覆盖配置值。 可以在运行应用程序之前就组成和覆盖配置。 动态命令行选项卡完成功能可帮助开发人员发现复杂配置并减少错误。 可以在本地或远程启动应用程序,使用户可以利用更多的本地资源。 MLflow Tracking MLflow 是一个开放源代码库,用于管理机器学习试验的生命周期。 MLFlow 跟踪是 MLflow 的一个组件,它可以记录和跟踪训练运行指标及模型项目,无论试验环境是在本地计算机上、远程计算目标上、虚拟机上,还是在 Azure Databricks 群集上。 执行过程 实验跟踪记录 Optuna 优化历史 参数关系 参数重要性 参数列表 环境部署 optuna-dashboard Dockerfile FROM node:14 AS front-builder WORKDIR /usr/src ADD ./package.json /usr/src/package.json ADD ./package-lock.json /usr/src/package-lock.json RUN npm install --registry=https://registry.npm.taobao.org ADD ./tsconfig.json /usr/src/tsconfig.json ADD ./webpack.config.js /usr/src/webpack.config.js ADD .