Jupyter Notebook弹性使用Kubernetes集群GPU资源
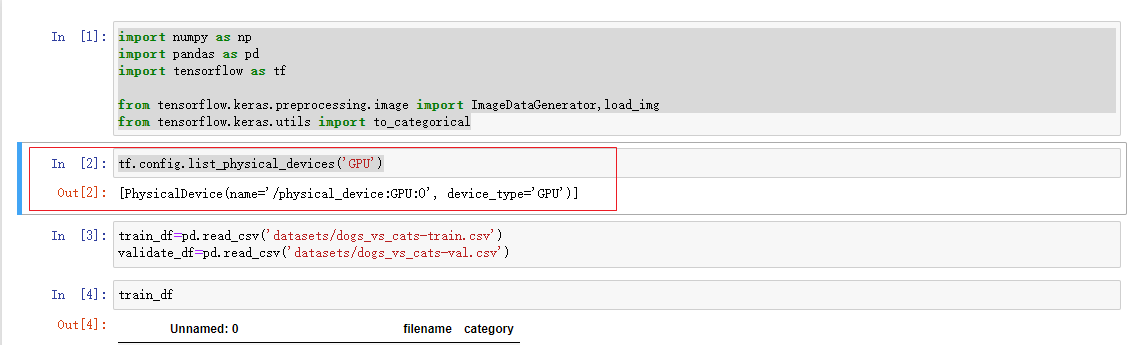
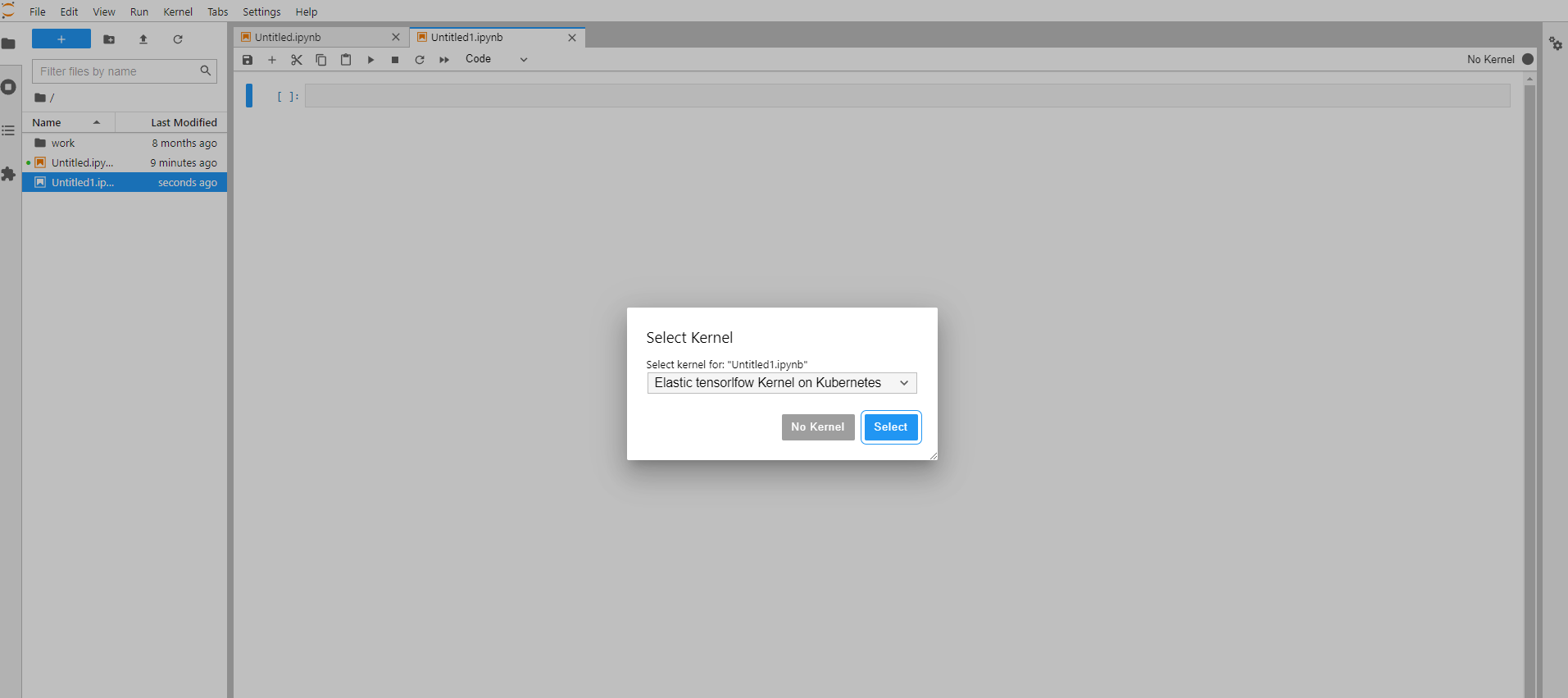
在前面介绍了Kubernetes集群中提高GPU资源使用率的两个途径:1,GPU虚拟化,共享使用GPU。2,弹性调度,动态地创建和销毁占用GPU资源的Jupyter Pod。今天主要介绍如何通过腾讯开源的tkestack/elastic-jupyter-operator实现GPU资源弹性调度。 弹性调度原理 Jupyter Enterprise Gateway Jupyter Enterprise Gateway是一个支持多用户和多集群环境的可插拔框架。这样Jupyter Notebook能够在分布式集群中启动远程内核,远程内核可以在使用时创建,在空闲时销毁,不再需要一直占用宝贵的GPU资源。 tkestack/elastic-jupyter-operator 在使用Jupyter Enterprise Gateway过程中,我们需要将远程内核配置到Gateway注册,启动远程内核实例。elastic-jupyter-operator解决了这个过程自动化问题,动态地管理内核,为Gateway生成内核配置,并增加了KernelLauncher新方法,实现Kernel Pod的生命周期管理。通过kubeflow-launcher在Kubernetes中创建jupyter kernel Pod,当Kernel空闲时,删除Kernel的CR,实现Kernel占用资源的回收释放。 部署使用 部署elastic-jupyter-operator kubectl apply -f ./hack/enterprise_gateway/prepare.yaml make deploy 创建Gateway CR apiVersion: kubeflow.tkestack.io/v1alpha1 kind: JupyterGateway metadata: name: jupytergateway-elastic-tensorflow spec: cullIdleTimeout: 10 cullInterval: 10 logLevel: DEBUG image: ccr.ccs.tencentyun.com/kubeflow-oteam/enterprise-gateway:dev # Use the kernel which is defined in JupyterKernelSpec CR. defaultKernel: python-tensorflow kernels: - python-tensorflow 创建KernelSpec CR和KernelTemplate CR apiVersion: kubeflow.tkestack.io/v1alpha1 kind: JupyterKernelSpec metadata: name: python-tensorflow spec: language: Python displayName: "Elastic tensorlfow Kernel on Kubernetes" image: elyra/kernel-tf-py:2.