机器学习部署模型服务
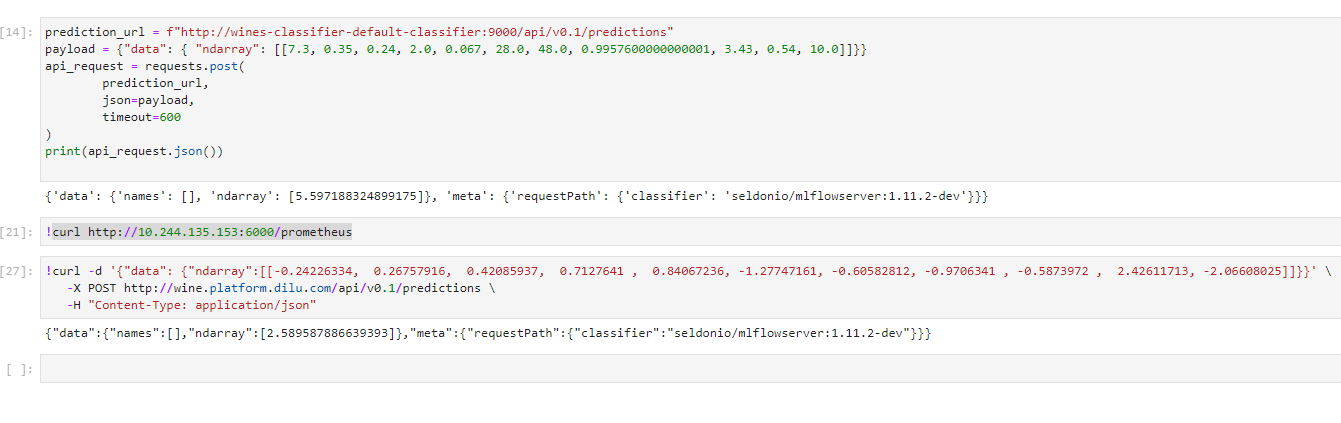
当训练好了一个模型,如何对外提供推理服务。Seldon Core是在Kubernetes上部署机器学习模型的流行组件。简单地说,Seldon Core将模型封装成生产级的REST/GRPC微服务。Seldon Core已与Istio、Jeager、Prometheus做了集成,支持灰度发布、A/B测试、链路跟踪、指标监控等。 今天给大家示例的是最简化的使用方式,仅有Seldon Core,无其他开源组件。我只想用Seldon Core来完成我的模型加载和提供API服务。 | 部署Seldon Core Operator 编辑values.yaml,禁用ambassador, istio ambassador: enabled: false istio: enabled: false 因为我的Kubernetes集群版本v1.22.2,所以要修改一下webhook.yaml里的协议版本 sideEffects: None admissionReviewVersions: - v1beta1 | 安装 helm install -n seldon-system seldon-core-operator seldon-core-operator | Prefect工作流 Prefect agent role添加seldon API操作权限 - apiGroups: - machinelearning.seldon.io resources: - seldondeployments verbs: - '*' | 修改模型训练任务 在训练模型任务返回MLflow的run_id,归档模型文件时,不注册模型版本 @task def train_model(data, mlflow_experiment_id, alpha=0.5, l1_ratio=0.5): mlflow.set_tracking_uri(f'http://mlflow.platform.sukai.com/') train, test = train_test_split(data) # The predicted column is "quality" which is a scalar from [3, 9] train_x = train.