由 SuKai August 15, 2021
Rook 是一个可以提供 Ceph 集群管理能力的 Operator。Rook 使用 CRD 一个控制器来对 Ceph 之类的资源进行部署和管理。Rook Ceph要求存储设备为块设备,支持分区或者整块硬盘。
| 磁盘分区
sukai@ceph-01:~$ sudo pvcreate /dev/sda
WARNING: ext4 signature detected on /dev/sda at offset 1080. Wipe it? [y/n]: y
Wiping ext4 signature on /dev/sda.
Physical volume "/dev/sda" successfully created.
sukai@ceph-01:~$ sudo vgcreate data /dev/sda
Volume group "data" successfully created
sukai@ceph-01:~$ sudo pvs
PV VG Fmt Attr PSize PFree
/dev/sda data lvm2 a-- <9.10t <9.10t
sukai@ceph-01:~$ sudo vgs
VG #PV #LV #SN Attr VSize VFree
data 1 0 0 wz--n- <9.10t <9.10t
sukai@ceph-01:~$
sukai@ceph-01:~$ sudo lvcreate -L 1024G -n lv1 data
Logical volume "lv1" created.
sukai@ceph-01:~$ sudo vgs
VG #PV #LV #SN Attr VSize VFree
data 1 4 0 wz--n- <9.10t <5.10t
sukai@ceph-01:~$ sudo lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lv1 data -wi-a----- 1.00t
lv2 data -wi-a----- 1.00t
lv3 data -wi-a----- 1.00t
lv4 data -wi-a----- 1.00t
sukai@ceph-01:~/sukai/ceph$ lsblk -f
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
loop0 squashfs 0 100% /snap/core18/1988
loop1 squashfs 0 100% /snap/bare/5
loop2 squashfs 0 100% /snap/core18/2253
loop3 squashfs 0 100% /snap/gnome-3-34-1804/66
loop4 squashfs 0 100% /snap/gnome-3-34-1804/77
loop5 squashfs 0 100% /snap/gtk-common-themes/1514
loop6 squashfs 0 100% /snap/gtk-common-themes/1519
loop7 squashfs 0 100% /snap/gnome-3-38-2004/87
loop8 squashfs 0 100% /snap/snapd/11036
loop9 squashfs 0 100% /snap/snapd/14066
loop10 squashfs 0 100% /snap/snap-store/518
loop11 squashfs 0 100% /snap/core20/1242
loop12 squashfs 0 100% /snap/snap-store/558
sda LVM2_member 1GlwRl-CMVl-PHdb-3RJe-p7r0-Wisd-x1EdxW
├─data-lv1
├─data-lv2
├─data-lv3
└─data-lv4
nvme0n1
├─nvme0n1p1 vfat 000B-2326 505.8M 1% /boot/efi
└─nvme0n1p2 ext4 d63faaf1-b460-4d9b-9384-aa2d78690656 87.3G 20% /
| 创建StorageClass和PersistentVolume
sukai@ceph-01:~/sukai/ceph$ cat storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: manual
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
sukai@ceph-01:~/sukai/ceph$ cat cluster-sukai-pvc.yaml
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: data-lv1
spec:
storageClassName: manual
capacity:
storage: 1024Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
volumeMode: Block
local:
path: /dev/disk/by-id/dm-name-data-lv1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- ceph-01
---
| 部署Rook operator
kubectl apply -f common.yaml -f crds.yaml -f operator.yaml
| 配置Rook使用的镜像
kubectl -n rook-ceph edit configmap rook-ceph-operator-config
apiVersion: v1
data:
CSI_CEPHFS_FSGROUPPOLICY: None
CSI_ENABLE_CEPHFS_SNAPSHOTTER: "true"
CSI_ENABLE_RBD_SNAPSHOTTER: "true"
CSI_ENABLE_VOLUME_REPLICATION: "false"
CSI_FORCE_CEPHFS_KERNEL_CLIENT: "true"
CSI_PROVISIONER_REPLICAS: "2"
CSI_RBD_FSGROUPPOLICY: ReadWriteOnceWithFSType
ROOK_CEPH_COMMANDS_TIMEOUT_SECONDS: "15"
ROOK_CSI_ALLOW_UNSUPPORTED_VERSION: "false"
ROOK_CSI_ATTACHER_IMAGE: longhornio/csi-attacher:v3.2.1
ROOK_CSI_ENABLE_CEPHFS: "true"
ROOK_CSI_ENABLE_GRPC_METRICS: "false"
ROOK_CSI_ENABLE_RBD: "true"
ROOK_CSI_PROVISIONER_IMAGE: longhornio/csi-provisioner:v2.1.2
ROOK_CSI_REGISTRAR_IMAGE: longhornio/csi-node-driver-registrar:v2.3.0
ROOK_CSI_RESIZER_IMAGE: longhornio/csi-resizer:v1.2.0
ROOK_CSI_SNAPSHOTTER_IMAGE: longhornio/csi-snapshotter:v3.0.3
ROOK_CSI_ATTACHER_IMAGE: longhornio/csi-attacher:v3.2.1
ROOK_ENABLE_DISCOVERY_DAEMON: "false"
ROOK_ENABLE_FLEX_DRIVER: "false"
ROOK_LOG_LEVEL: INFO
ROOK_OBC_WATCH_OPERATOR_NAMESPACE: "true"
kind: ConfigMap
| 创建Ceph集群的配置
因为是单点集群,默认副本数会告警,所以修改默认配置。
sukai@ceph-01:~/sukai/ceph$ cat cluster-sukai-pvc-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: rook-config-override
namespace: rook-ceph # namespace:cluster
data:
config: |
[global]
osd_pool_default_size = 1
osd_pool_default_min_size = 1
mon_warn_on_pool_no_redundancy = false
bdev_flock_retry = 20
bluefs_buffered_io = false
| 创建Ceph集群
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
cephVersion:
image: quay.io/ceph/ceph:v16.2.6
allowUnsupported: false
dataDirHostPath: /opt/rook
skipUpgradeChecks: false
continueUpgradeAfterChecksEvenIfNotHealthy: false
waitTimeoutForHealthyOSDInMinutes: 10
mon:
count: 1
allowMultiplePerNode: true
mgr:
count: 1
modules:
- name: pg_autoscaler
enabled: true
sukaird:
enabled: true
ssl: false
monitoring:
enabled: false
rulesNamespace: rook-ceph
network:
provider: host
crashCollector:
disable: false
#daysToRetain: 30
cleanupPolicy:
confirmation: ""
sanitizeDisks:
method: quick
dataSource: zero
iteration: 1
allowUninstallWithVolumes: false
annotations:
labels:
resources:
removeOSDsIfOutAndSafeToRemove: false
storage:
storageClassDeviceSets:
- name: set1
count: 4
portable: false
tuneDeviceClass: true
volumeClaimTemplates:
- metadata:
name: data
spec:
resources:
requests:
storage: 900Gi
storageClassName: manual
volumeMode: Block
accessModes:
- ReadWriteOnce
onlyApplyOSDPlacement: false
placement:
all:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- ceph-01
disruptionManagement:
managePodBudgets: false
osdMaintenanceTimeout: 30
pgHealthCheckTimeout: 0
manageMachineDisruptionBudgets: false
machineDisruptionBudgetNamespace: openshift-machine-api
healthCheck:
daemonHealth:
mon:
disabled: false
interval: 45s
osd:
disabled: false
interval: 60s
status:
disabled: false
interval: 60s
livenessProbe:
mon:
disabled: false
mgr:
disabled: false
osd:
disabled: false
| 创建文件系统
sukai@ceph-01:~/sukai/ceph$ cat filesystem.yaml
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: ai
namespace: rook-ceph
spec:
metadataPool:
failureDomain: host
replicated:
size: 1
dataPools:
- failureDomain: host
replicated:
size: 1
preserveFilesystemOnDelete: true
metadataServer:
activeCount: 1
activeStandby: true
# A key/value list of annotations
annotations:
# key: value
placement:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: role
# operator: In
# values:
# - mds-node
# tolerations:
# - key: mds-node
# operator: Exists
# podAffinity:
# podAntiAffinity:
# topologySpreadConstraints:
resources:
# limits:
# cpu: "500m"
# memory: "1024Mi"
# requests:
# cpu: "500m"
# memory: "1024Mi"
| 创建NFS服务
sukai@ceph-01:~/sukai/ceph$ cat nfs.yaml
apiVersion: ceph.rook.io/v1
kind: CephNFS
metadata:
name: ai-nfs
namespace: rook-ceph
spec:
# rados property is not used in versions of Ceph equal to or greater than
# 16.2.7, see note in RADOS settings section below.
rados:
# RADOS pool where NFS client recovery data and per-daemon configs are
# stored. In this example the data pool for the "myfs" filesystem is used.
# If using the object store example, the data pool would be
# "my-store.rgw.buckets.data". Note that this has nothing to do with where
# exported CephFS' or objectstores live.
pool: ai-data0
# RADOS namespace where NFS client recovery data is stored in the pool.
namespace: nfs-ns
# Settings for the NFS server
server:
# the number of active NFS servers
active: 1
# A key/value list of annotations
annotations:
# key: value
# where to run the NFS server
placement:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: role
# operator: In
# values:
# - mds-node
# tolerations:
# - key: mds-node
# operator: Exists
# podAffinity:
# podAntiAffinity:
# topologySpreadConstraints:
# The requests and limits set here allow the ganesha pod(s) to use half of one CPU core and 1 gigabyte of memory
resources:
# limits:
# cpu: "500m"
# memory: "1024Mi"
# requests:
# cpu: "500m"
# memory: "1024Mi"
# the priority class to set to influence the scheduler's pod preemption
priorityClassName:
| 创建toolbox
sukai@ceph-01:~/sukai/ceph$ cat toolbox.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: rook-ceph-tools
namespace: rook-ceph
labels:
app: rook-ceph-tools
spec:
replicas: 1
selector:
matchLabels:
app: rook-ceph-tools
template:
metadata:
labels:
app: rook-ceph-tools
spec:
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: rook-ceph-tools
image: rook/ceph:v1.7.8
command: ["/tini"]
args: ["-g", "--", "/usr/local/bin/toolbox.sh"]
imagePullPolicy: IfNotPresent
env:
- name: ROOK_CEPH_USERNAME
valueFrom:
secretKeyRef:
name: rook-ceph-mon
key: ceph-username
- name: ROOK_CEPH_SECRET
valueFrom:
secretKeyRef:
name: rook-ceph-mon
key: ceph-secret
volumeMounts:
- mountPath: /etc/ceph
name: ceph-config
- name: mon-endpoint-volume
mountPath: /etc/rook
volumes:
- name: mon-endpoint-volume
configMap:
name: rook-ceph-mon-endpoints
items:
- key: data
path: mon-endpoints
- name: ceph-config
emptyDir: {}
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 5
| 在toolbox中开启NFS挂载点管理
ceph sukaird set-ganesha-clusters-rados-pool-namespace ai:nfs-ganesha/ai-nfs
| 创建sukaird Ingress服务
sukai@ceph-01:~/sukai/ceph$ cat cluster-sukai-pvc-ingress.yaml
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ceph-sukaird
namespace: rook-ceph
annotations:
kubernetes.io/ingress.class: traefik
spec:
rules:
- host: ceph.platform.sukai.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: rook-ceph-mgr-sukaird
port:
name: http-sukaird
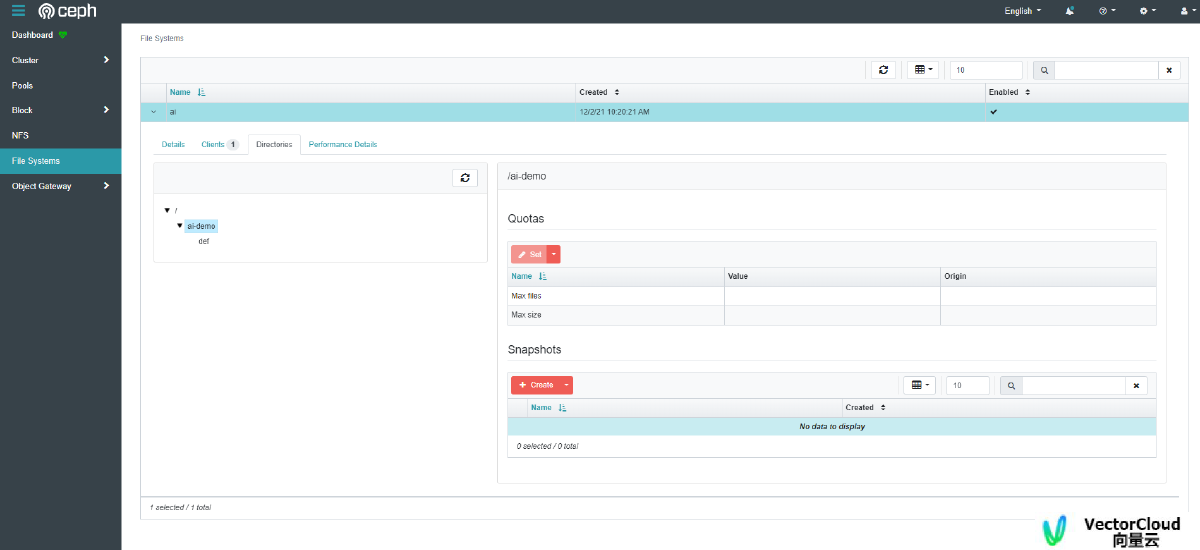
| 访问sukaird
kubectl -n rook-ceph get secret rook-ceph-sukaird-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
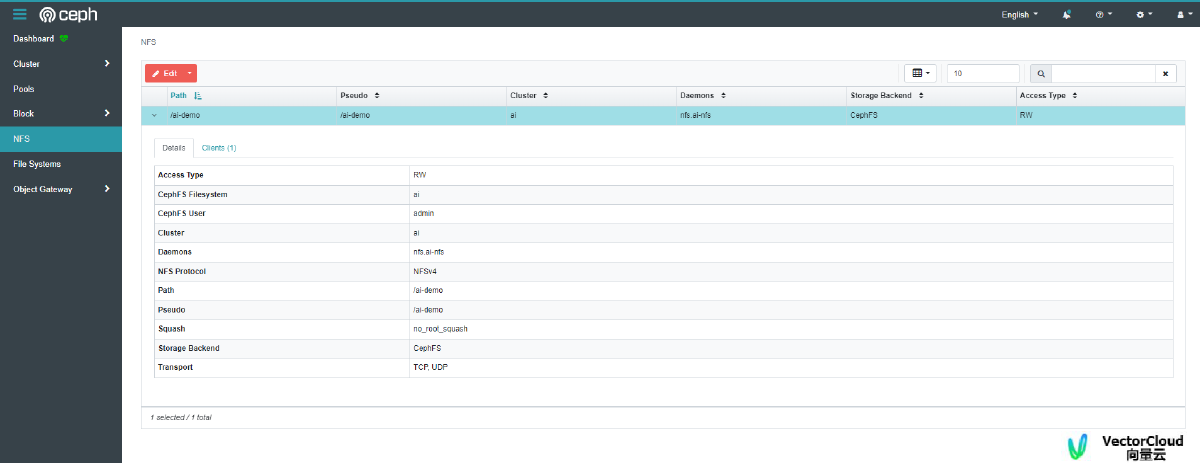
| 访问NFS服务
hello@hello-Precision-7920-Rack:~$ sudo mount -t nfs 192.168.10.7:/ai-demo/ /tmp/test
hello@hello-Precision-7920-Rack:~$ cd /tmp/test/
hello@hello-Precision-7920-Rack:/tmp/test$ ls
a def
hello@hello-Precision-7920-Rack:/tmp/test$
|查看文件系统目录