由 SuKai August 5, 2021
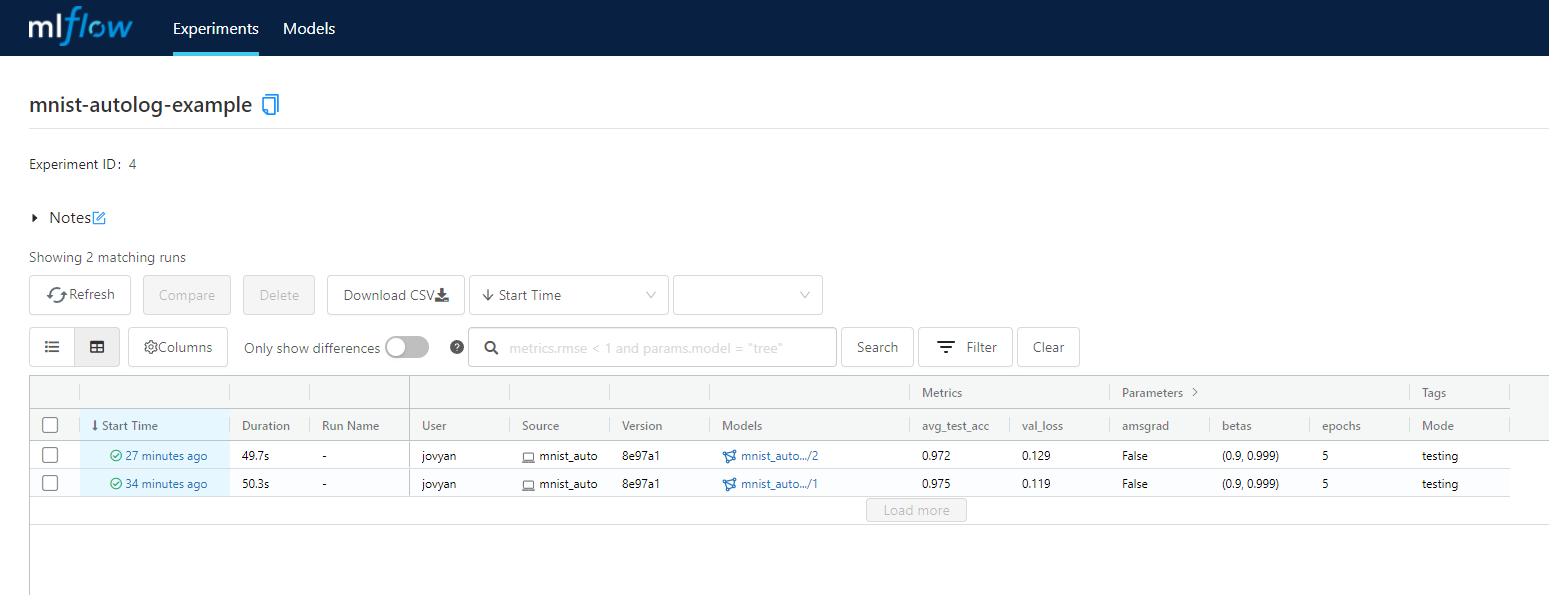
在开发人员进行模型开发迭代的过程中,会进行不断的参数和模型调整,对照训练结果,找出最佳参数。Databricks开源组件MLflow解决了这个过程记录问题。
MLflow主要功能
跟踪、记录实验过程,交叉比较实验参数和对应的结果(MLflow Tracking). 把代码打包成可复用、可复现的格式,可用于成员分享和针对线上部署(MLflow Project). 管理、部署来自多个不同机器学习框架的模型到大部分模型部署和推理平台(MLflow Models). 针对模型的全生命周期管理的需求,提供集中式协同管理,包括模型版本管理、模型状态转换、数据标注(MLflow Model Registry).
安装部署
这里使用sqlite作为mlflow的Meta数据存储,支持PostgreSQL数据库,使用Minio作为模型和归档文件存储
export MLFLOW_S3_ENDPOINT_URL=http://192.168.10.243:32234/
export AWS_ACCESS_KEY_ID="minio"
export AWS_SECRET_ACCESS_KEY="minio123"
export ARTIFACT_ROOT=s3://mlflow/
export BACKEND_URI=sqlite:////home/sukai/mlflow-server/mlflow.db
mlflow server --backend-store-uri ${BACKEND_URI} --default-artifact-root ${ARTIFACT_ROOT} --host 0.0.0.0 --port 5000
训练代码
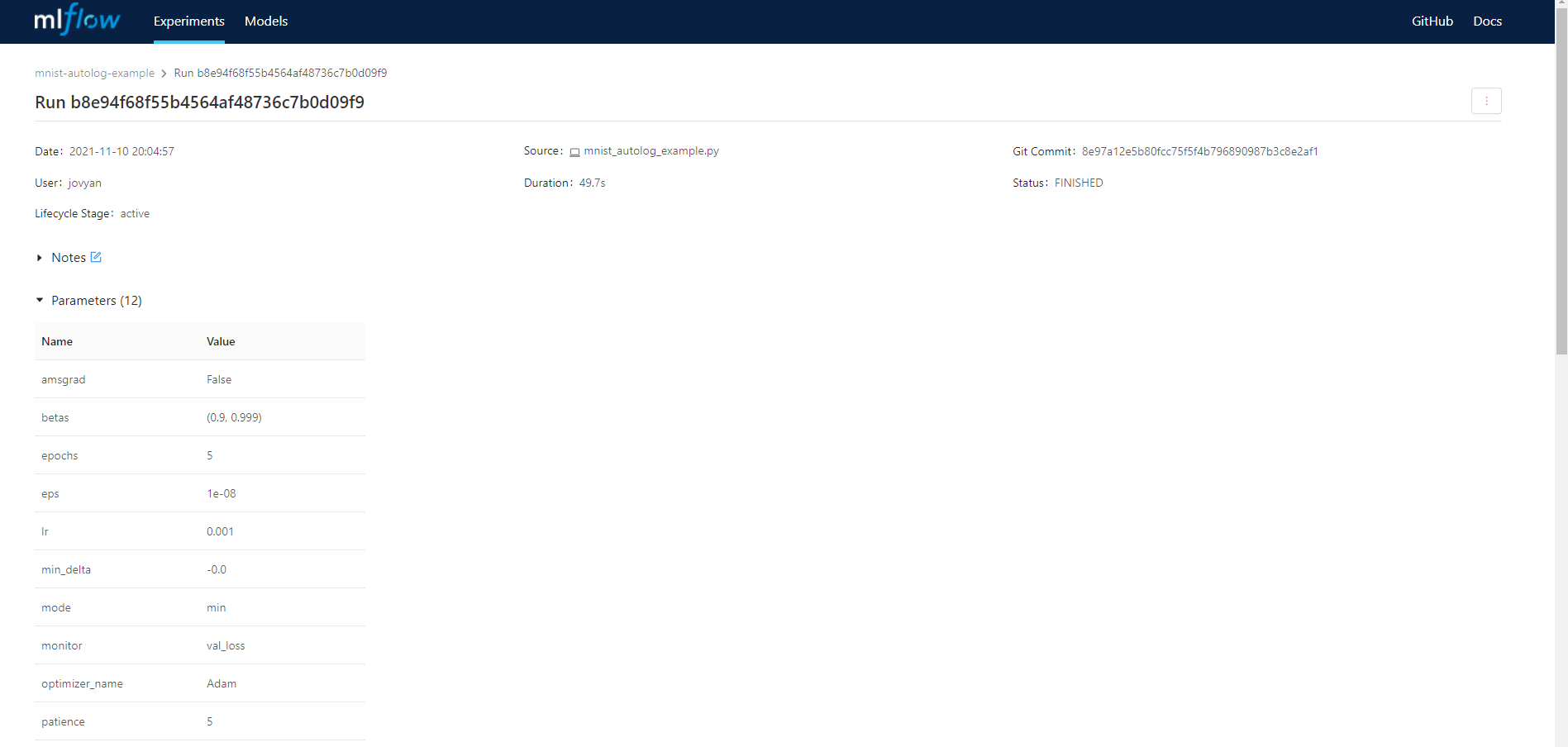
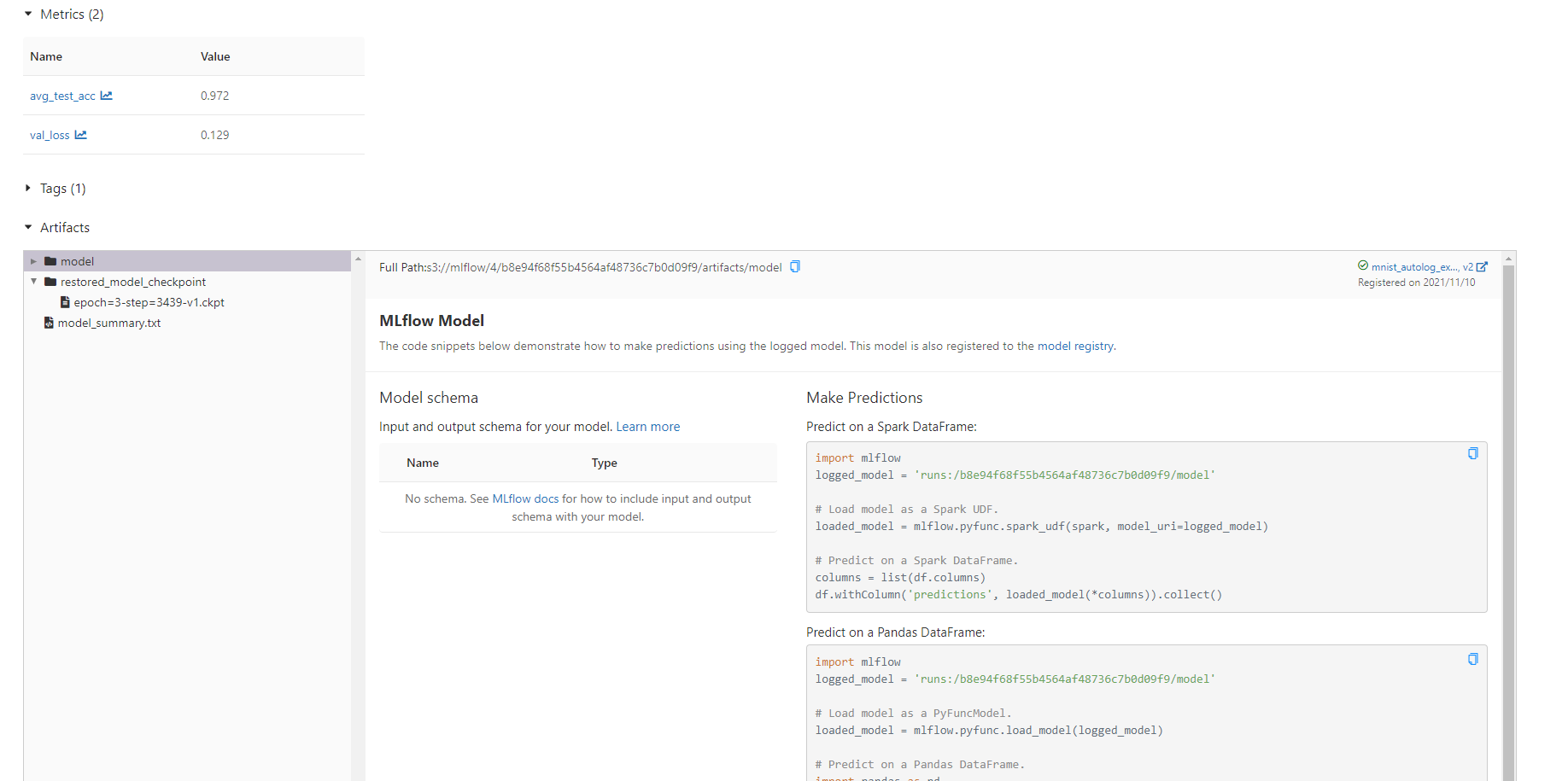
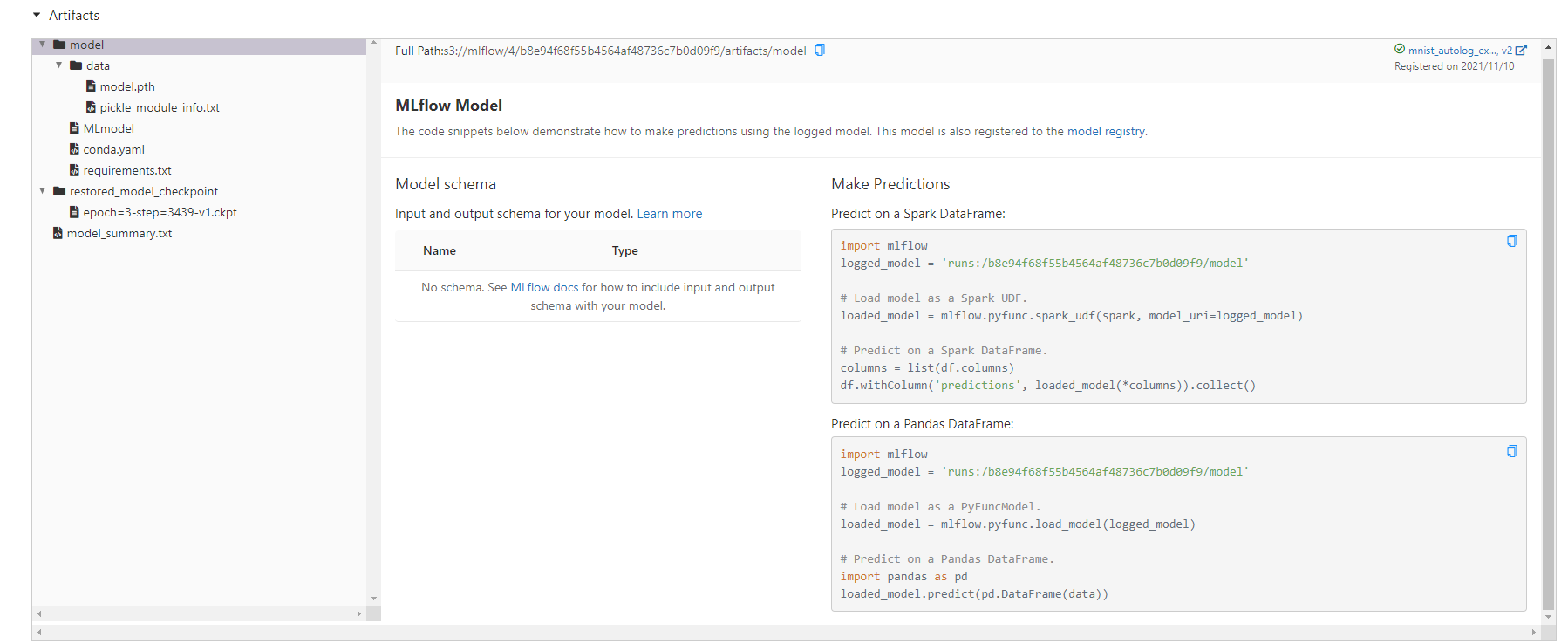
MLflow支持多机器学习框架Automatic Logging:Pytorch, TensorFlow, Scikit-learn…,只需加入少量代码,MLflow自动记录对应的参数与指标
#
# Trains an MNIST digit recognizer using PyTorch Lightning,
# and uses Mlflow to log metrics, params and artifacts
# NOTE: This example requires you to first install
# pytorch-lightning (using pip install pytorch-lightning)
# and mlflow (using pip install mlflow).
#
# pylint: disable=arguments-differ
# pylint: disable=unused-argument
# pylint: disable=abstract-method
import pytorch_lightning as pl
import mlflow.pytorch
import os
import torch
from argparse import ArgumentParser
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.callbacks import LearningRateMonitor
from torch.nn import functional as F
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "minio123"
os.environ["MLFLOW_S3_ENDPOINT_URL"] = f"http://192.168.10.243:32234/"
try:
from torchmetrics.functional import accuracy
except ImportError:
from pytorch_lightning.metrics.functional import accuracy
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, **kwargs):
"""
Initialization of inherited lightning data module
"""
super(MNISTDataModule, self).__init__()
self.df_train = None
self.df_val = None
self.df_test = None
self.train_data_loader = None
self.val_data_loader = None
self.test_data_loader = None
self.args = kwargs
# transforms for images
self.transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
def setup(self, stage=None):
"""
Downloads the data, parse it and split the data into train, test, validation data
:param stage: Stage - training or testing
"""
self.df_train = datasets.MNIST(
"dataset", download=True, train=True, transform=self.transform
)
self.df_train, self.df_val = random_split(self.df_train, [55000, 5000])
self.df_test = datasets.MNIST(
"dataset", download=True, train=False, transform=self.transform
)
def create_data_loader(self, df):
"""
Generic data loader function
:param df: Input tensor
:return: Returns the constructed dataloader
"""
return DataLoader(
df, batch_size=self.args["batch_size"], num_workers=self.args["num_workers"],
)
def train_dataloader(self):
"""
:return: output - Train data loader for the given input
"""
return self.create_data_loader(self.df_train)
def val_dataloader(self):
"""
:return: output - Validation data loader for the given input
"""
return self.create_data_loader(self.df_val)
def test_dataloader(self):
"""
:return: output - Test data loader for the given input
"""
return self.create_data_loader(self.df_test)
class LightningMNISTClassifier(pl.LightningModule):
def __init__(self, **kwargs):
"""
Initializes the network
"""
super(LightningMNISTClassifier, self).__init__()
# mnist images are (1, 28, 28) (channels, width, height)
self.optimizer = None
self.scheduler = None
self.layer_1 = torch.nn.Linear(28 * 28, 128)
self.layer_2 = torch.nn.Linear(128, 256)
self.layer_3 = torch.nn.Linear(256, 10)
self.args = kwargs
@staticmethod
def add_model_specific_args(parent_parser):
parser = ArgumentParser(parents=[parent_parser], add_help=False)
parser.add_argument(
"--batch_size",
type=int,
default=64,
metavar="N",
help="input batch size for training (default: 64)",
)
parser.add_argument(
"--num_workers",
type=int,
default=3,
metavar="N",
help="number of workers (default: 3)",
)
parser.add_argument(
"--lr", type=float, default=0.001, metavar="LR", help="learning rate (default: 0.001)",
)
return parser
def forward(self, x):
"""
:param x: Input data
:return: output - mnist digit label for the input image
"""
batch_size = x.size()[0]
# (b, 1, 28, 28) -> (b, 1*28*28)
x = x.view(batch_size, -1)
# layer 1 (b, 1*28*28) -> (b, 128)
x = self.layer_1(x)
x = torch.relu(x)
# layer 2 (b, 128) -> (b, 256)
x = self.layer_2(x)
x = torch.relu(x)
# layer 3 (b, 256) -> (b, 10)
x = self.layer_3(x)
# probability distribution over labels
x = torch.log_softmax(x, dim=1)
return x
def cross_entropy_loss(self, logits, labels):
"""
Initializes the loss function
:return: output - Initialized cross entropy loss function
"""
return F.nll_loss(logits, labels)
def training_step(self, train_batch, batch_idx):
"""
Training the data as batches and returns training loss on each batch
:param train_batch: Batch data
:param batch_idx: Batch indices
:return: output - Training loss
"""
x, y = train_batch
logits = self.forward(x)
loss = self.cross_entropy_loss(logits, y)
return {"loss": loss}
def validation_step(self, val_batch, batch_idx):
"""
Performs validation of data in batches
:param val_batch: Batch data
:param batch_idx: Batch indices
:return: output - valid step loss
"""
x, y = val_batch
logits = self.forward(x)
loss = self.cross_entropy_loss(logits, y)
return {"val_step_loss": loss}
def validation_epoch_end(self, outputs):
"""
Computes average validation accuracy
:param outputs: outputs after every epoch end
:return: output - average valid loss
"""
avg_loss = torch.stack([x["val_step_loss"] for x in outputs]).mean()
self.log("val_loss", avg_loss, sync_dist=True)
def test_step(self, test_batch, batch_idx):
"""
Performs test and computes the accuracy of the model
:param test_batch: Batch data
:param batch_idx: Batch indices
:return: output - Testing accuracy
"""
x, y = test_batch
output = self.forward(x)
_, y_hat = torch.max(output, dim=1)
test_acc = accuracy(y_hat.cpu(), y.cpu())
return {"test_acc": test_acc}
def test_epoch_end(self, outputs):
"""
Computes average test accuracy score
:param outputs: outputs after every epoch end
:return: output - average test loss
"""
avg_test_acc = torch.stack([x["test_acc"] for x in outputs]).mean()
self.log("avg_test_acc", avg_test_acc)
def configure_optimizers(self):
"""
Initializes the optimizer and learning rate scheduler
:return: output - Initialized optimizer and scheduler
"""
self.optimizer = torch.optim.Adam(self.parameters(), lr=self.args["lr"])
self.scheduler = {
"scheduler": torch.optim.lr_scheduler.ReduceLROnPlateau(
self.optimizer, mode="min", factor=0.2, patience=2, min_lr=1e-6, verbose=True,
),
"monitor": "val_loss",
}
return [self.optimizer], [self.scheduler]
if __name__ == "__main__":
parser = ArgumentParser(description="PyTorch Autolog Mnist Example")
# Early stopping parameters
parser.add_argument(
"--es_monitor", type=str, default="val_loss", help="Early stopping monitor parameter"
)
parser.add_argument("--es_mode", type=str, default="min", help="Early stopping mode parameter")
parser.add_argument(
"--es_verbose", type=bool, default=True, help="Early stopping verbose parameter"
)
parser.add_argument(
"--es_patience", type=int, default=3, help="Early stopping patience parameter"
)
parser = pl.Trainer.add_argparse_args(parent_parser=parser)
parser = LightningMNISTClassifier.add_model_specific_args(parent_parser=parser)
mlflow.set_tracking_uri('http://192.168.10.226:5000')
mlflow.set_experiment(experiment_name='mnist-autolog-example')
mlflow.pytorch.autolog()
args = parser.parse_args()
dict_args = vars(args)
if "accelerator" in dict_args:
if dict_args["accelerator"] == "None":
dict_args["accelerator"] = None
model = LightningMNISTClassifier(**dict_args)
dm = MNISTDataModule(**dict_args)
dm.setup(stage="fit")
early_stopping = EarlyStopping(
monitor=dict_args["es_monitor"],
mode=dict_args["es_mode"],
verbose=dict_args["es_verbose"],
patience=dict_args["es_patience"],
)
checkpoint_callback = ModelCheckpoint(
dirpath=os.getcwd(), save_top_k=1, verbose=True, monitor="val_loss", mode="min"
)
lr_logger = LearningRateMonitor()
trainer = pl.Trainer.from_argparse_args(
args, callbacks=[lr_logger, early_stopping, checkpoint_callback], checkpoint_callback=True
)
trainer.fit(model, dm)
trainer.test()
开始训练
!python mnist_autolog_example.py \
--max_epochs 5 \
--gpus 0 \
--accelerator "ddp" \
--batch_size 64 \
--num_workers 3 \
--lr 0.001 \
--es_patience 5 \
--es_mode "min" \
--es_monitor "val_loss" \
--es_verbose True
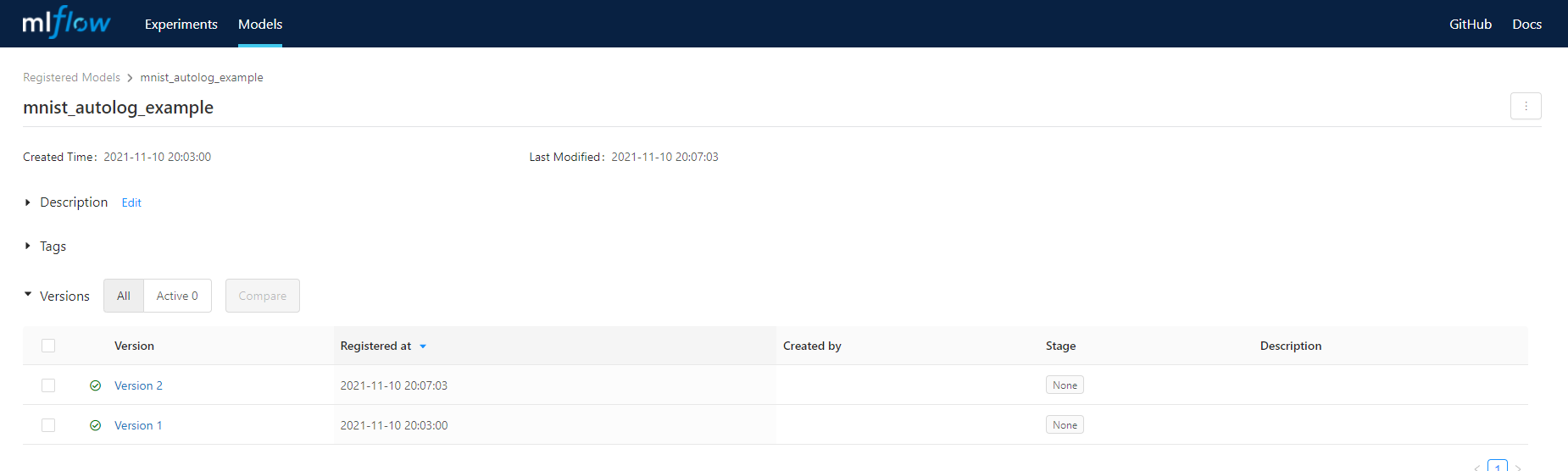
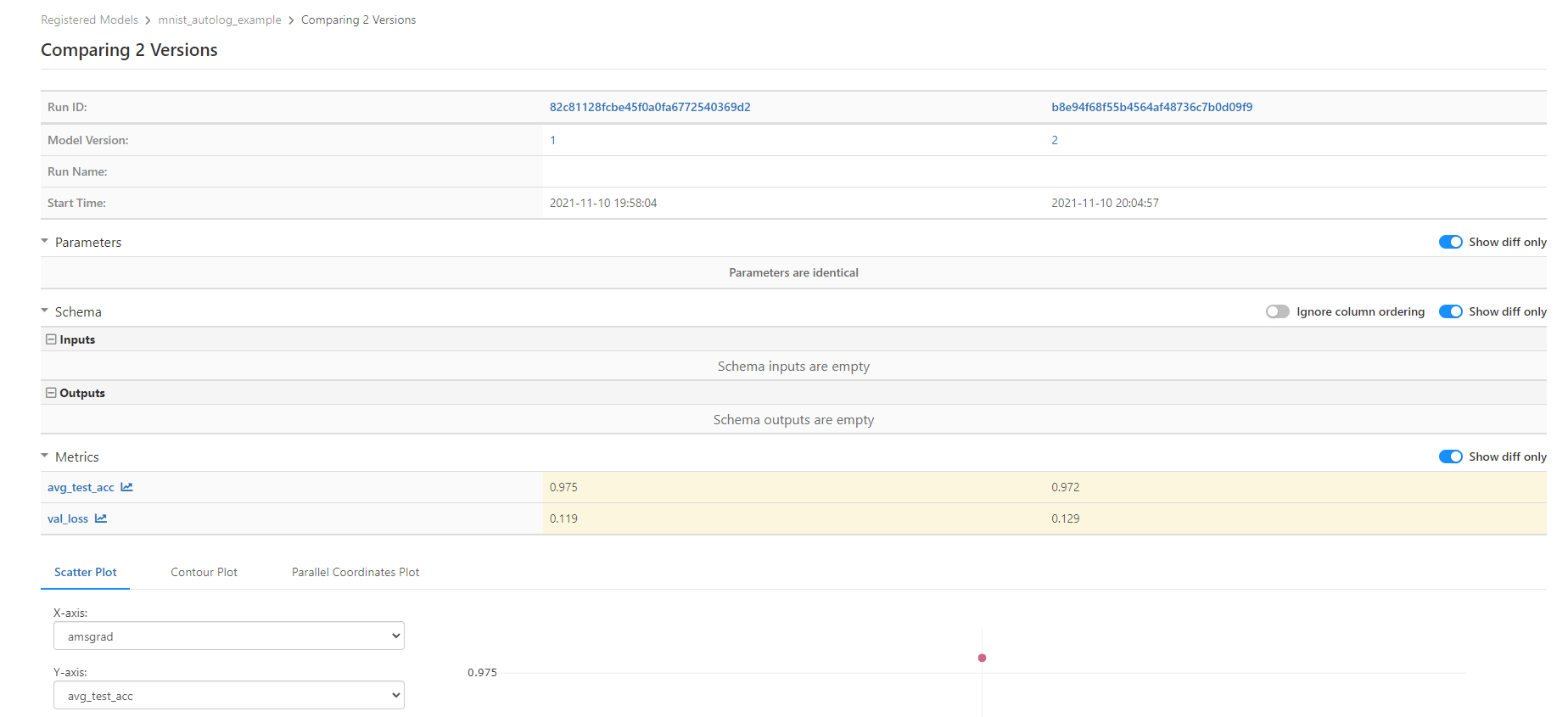
查看训练实验报告