由 SuKai August 2, 2021
在Kubernetes集群中如何提高算力资源使用效率一直受到用户关注,公司内部有限GPU资源如何得到充分利用,1,GPU虚拟化,将GPU硬件由独享变成共享使用;2,弹性调度,当申请占用的GPU资源空闲时,释放资源给有需要的用户使用。本篇先介绍如何将GPU虚拟化,如何使用虚拟化的GPU资源。GPU虚拟化的开源解决方案有几个,我们选择的是阿里云的GPU共享方案。
| 安装Nvidia Docker运行时
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
sudo apt install nvidia-container-toolkit
sudo systemctl restart docker
sudo tee /etc/docker/daemon.json <<EOF
{
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn","http://hub-mirror.c.163.com"],
"storage-driver": "overlay2",
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
EOF
sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
Mon Nov 1 11:20:19 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.63.01 Driver Version: 470.63.01 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Quadro RTX 4000 Off | 00000000:65:00.0 Off | N/A |
| 30% 29C P8 9W / 125W | 7446MiB / 7982MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
| 安装阿里云组件
cd /etc/kubernetes/
curl -O https://raw.githubusercontent.com/AliyunContainerService/gpushare-scheduler-extender/master/config/scheduler-policy-config.json
cd /tmp/
curl -O https://raw.githubusercontent.com/AliyunContainerService/gpushare-scheduler-extender/master/config/gpushare-schd-extender.yaml
kubectl create -f gpushare-schd-extender.yaml
配置Kubernetes调度器
sudo vi /etc/kubernetes/manifests/kube-scheduler.yaml
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --policy-config-file=/etc/kubernetes/scheduler-policy-config.json
- --leader-elect=true
- --port=0
kubectl apply -f device-plugin-rbac.yaml -f device-plugin-ds.yaml
对GPU节点增加标签
kubectl label node hello-precision-7920-rack gpushare=true
下载安装kubectl插件kubectl-inspect-gpushare,查看GPU信息
$ sudo cp kubectl-inspect-gpushare /usr/bin/
$ sudo chmod a+x /usr/bin/kubectl-inspect-gpushare
$ kubectl inspect gpushare
NAME IPADDRESS GPU0(Allocated/Total) GPU Memory(GiB)
hello-precision-7920-rack 192.168.0.244 4/7 4/7
--------------------------------------------------------------------
Allocated/Total GPU Memory In Cluster:
4/7 (57%)
部署Jupyter notebook,申请使用GPU资源
resources:
limits:
cpu: "8"
memory: 12Gi
aliyun.com/gpu-mem: 4
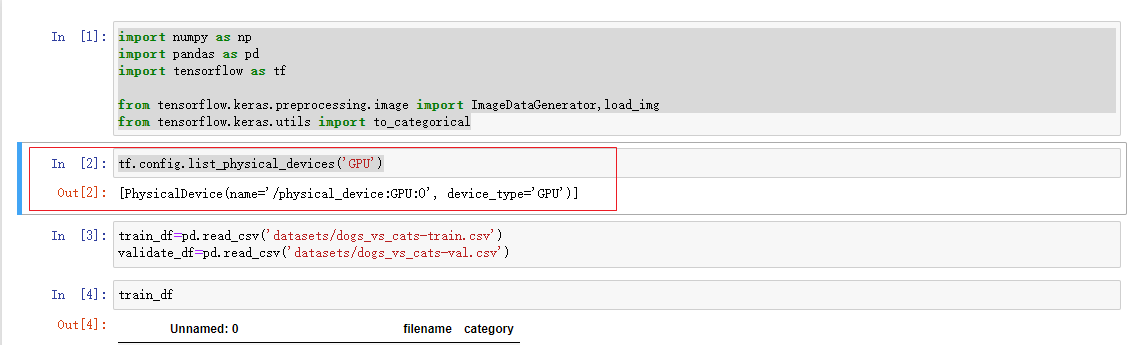
访问Jupyter,访问GPU资源
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator,load_img
from tensorflow.keras.utils import to_categorical
tf.config.list_physical_devices('GPU')